ツリーの水平順序とパターンの侵入性
Information Extractorとでも呼ぶべきソフトウェアについて、[extract]タグを付けて書く。系統的には書けないが、そのとき重要だと思ったことを書く。
Information Extractorのおよその構造は既に分かっている。式(expression)を使って文書ツリーから情報をJSON形式で抽出する。Tをツリー、aをツリーTのノード、EとBを式だとする。Information Extractorの中核は次の2つの関数になる。
- extract(T, a, E)
- eval(T, a, B)
extractとevalの戻り値はJSONデータ。この2つは相互再帰的に絡み合って動く。ツリーTは最初に与えられ固定されると思えば省略してもいい。
- extract(a, E)
- eval(a, B)
あるいはメソッド風に:
- T.extract(a, E)
- T.eval(a, B)
ノードaは評価の基点となるノードでコンテキストノードと呼ばれる。
さて、最近気が付いた重要なことがある。式の設計においても見逃していたために、どうも不自然なところがあった。見逃していたことは、ツリーの水平順序(horizontal order)と僕が名づけた順序構造である。そして、水平順序に関係する、パターンの侵入性(intrusiveness)という概念である。
パターン(式の一種)が侵入的(intrusive)か非侵入的(non-intrusive)かによって、挙動と結果は大きく変わる。今までは侵入的パターンしか考えてなかった。しかし、多くの場合は非侵入的パターンのほうが自然である。つまり、自然な挙動を定式化出来てなかった!
トップダウン順序と水平順序
ツリーの深さ優先再帰的トラバースから、ツリーのノード集合に2つの線形順序(全順序; linear order, total order)が導入される。トップダウン順序とボトムアップ順序だ。トップダウン順序は、行き掛けの順序、ボトムアップ順序は帰り掛けの順序とも呼ぶ。
トップダウン順序では、ルートが最初のノード。ボトムアップ順序では、ルートが最後のノードとなる。XMLの文書順序(document order)とは、トップダウン順序に他ならない。次の図は、トップダウン順序における「次のノード」を青い矢印で描いたもの。最後のノードには次がないのでバッテンを描いている。
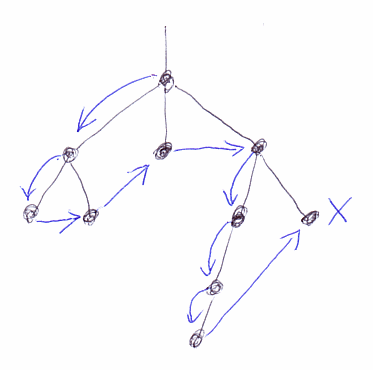
ボトムアップ順序は使わないので図示は省略。トップダウン順序とボトムアップ順序は、絵のイメージで上下方向への辿り(トラバース)が割と多いので、まとめて垂直順序と呼ぶことにする。
それに対して、水平順序は、辿りが水平方向(横方向)となる、あくまで絵のイメージだが。次の図は、水平順序における「次のノード」を赤い矢印で描いたもの。次がないノードにはバッテンを描いている。
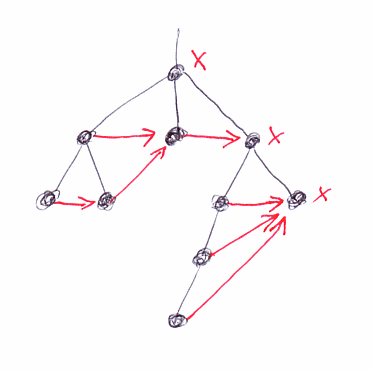
水平順序は線形順序ではない!したがって、最初のノードや最後のノードを特定できない。
水平順序の「次(直後)」の定義
ツリーの各ノードに対して、次(直後)のノードが定義できれば、それをもとに順序構造(部分順序; partial order)を定義できる。水平順序における「次(直後)のノード」は一意的に決まるか、存在しないかのどちらかである。
- 隣接する弟ノードがあれば、それが次のノードである。
- 弟ノードがないときは、親ノードの隣接する弟ノードを探す。あれば、それが次のノードである。
- 親ノードに弟ノードがないときは、さらにその親の弟を探す。
- 親を順に辿る操作が出来ない(ルートに達したら)、次のノードは存在しない。
感じとしては、水平順序の次ノードは、右横または右上方に存在する。
水平順序に沿ってトラバースすると、線形順序ではないので、部分的なトラバースしか出来ない。このトラバースは次の性質を持つ。
- トップダウン順序によるトラバースで既に辿った(訪れた)ノードを訪れることはない。
- 訪れたノードの子孫ノードを訪れることはない。
トップダウン順序と水平順序を併用したトラバース
[追記]概念の説明としては以下でもいいが、実際の挙動の記述としては不正確・不十分。http://d.hatena.ne.jp/m-hiyama-memo/20140313 の記事群を参照。[/追記]
ツリーのノードを順に訪れる処理は、ツリー構造に関するfoldと考えることができる。リストのフォールドが右foldrと左foldlがあるように、ノード集合の順序構造で挙動と結果が変わる。
ここでは、トップダウン順序と水平順序を併用したトラバースをツリー構造に対するフォールド関数として定義する。
- foldTree : NodeProc, Data, Tree -> (Data | null | undefined)
Dataはなんかデータ型として、Dataはnullとundefinedを含まないとする。NodeProcは高階の型(関数型)で、f∈NodeProc ならば、
- f:Node, Data -> (Data | null | undefined)
foldTreeは、ツリーTのノードaと、それまでに得られたデータxを使って f(a, x) を呼び出す。これをノード全体に渡って行う。-- と、まーそうなのだが、f(a, x) の値により「次のノード」を変える。
- f(a, x) の値がnullまたはundefinedのときは、累積値(それまでに得られたデータ)はxのままとして、トップダウン順序で次のノードを選ぶ。
- f(a, x) の値がnullまたはundefined以外のときは、累積値(それまでに得られたデータ)を f(a, x) に更新して、水平順序で次のノードを選ぶ。
侵入的パターンと非侵入的パターン
パターンとは情報抽出用の式(expression)の一種である。パターンには侵入性のフラグを付ける。侵入性フラグは、そのパターンを使うフォールド関数にトラバースの指示を与える。
foldTreeの引数となるノード処理関数(NodeProcのインスタンス)fは、extractでは次のように定義される。Pはパターンとする。
- eval(a, P) の値がnullまたはundefinedなら、その値(nullまたはundefined)が f(a, x) の値。
- eval(a, P) の値がnullまたはundefinedでないなら、f(a, x) = push(x, eval(a, P))。xはリストで、pushはリストの最後に項目を追加する関数。
侵入性フラグは各ノードごとの評価には影響しない。次のノードを選ぶときに影響する。
- 評価が失敗(結果がnullまたはundefined)のときは、侵入性フラグに関係なく、常にトップダウン順序を使って次のノードを決める。
- 侵入的パターンは、評価が成功のときも、トップダウン順序を使って次のノードを決める。(従来の方式)
- 非侵入的パターンは、評価が成功のときは、水平順序を使って次のノードを決める。
侵入性フラグのデフォルトと構文
パターンの侵入性フラグのデフォルトはOFF、つまり非侵入的パターンをデフォルトにするのが良いだろう。侵入的パターンが必要なときも多いのだが、侵入的だと直感に反してかなり混乱することがある。
構文的には、侵入性をONにする目印記号を決めて、侵入的パターンにはその目印を付けることになるだろう。
[追記]
パターンは、セレクターとそれに引き続く式を一緒にしたものだ。Perlのテキスト処理だと if(/正規表現/) { 処理 } のような感じ。正規表現の代わりに(平坦な)セレクター、処理の部分に抽出式が入る。カレントノード(現在見ているノード)がセレクターにマッチしたら引き続く処理(本体)が評価される。
現在の構文は、<セレクター> 本体の式 </> となっている。侵入的であることを表す記号を決めるんは非常に難しい。色々考えて、接頭辞としてバッククォート文字とか、かな。
* <div> $class </>
デフォルトが非侵入的なら、この式で入れ子の内側のdiv(div内のdiv)はマッチしない。
* `<div> $class </>
これは侵入的になるので、divを見つけても、その内側(子孫群)に入って入れ子のdivを探しに行く。
[さらに追記]
<セレクタ> 本体 </> という構文は、HTMLを強く連想させるのでかえって良くない気もする。/セレクタ/( 本体 ) とかがいいかもしれない。<div> $class </> のようだと、<div> $class </div> と思わず書いてしまう、ってのもあるし。
侵入的だと、
* `/div/( $class )
と、こうなる。
[さらにさらに追記]
水平順序によるトラバースは、次のように考えてもいい。foldTreeのような高階関数で、ノード処理関数(NodeProcの要素)に次々とノードを渡していくとする。そのとき、ノード処理関数が成功したら、そのノードの子孫すべてを「訪問済み」とマークする。もちろん、実際に訪問したノードも「訪問済み」だ。
このマーキングに関して、まだ「訪問済み」でない最初のノードが水平順序における次のノードになる。ノード処理関数が、ノードを相対ルートとするサブツリー全体を処理してしまい、サブツリー内ノードにそれ以上の処理が不要なときは、非侵入的トラバースがふさわしい。