HTTP上のRPCの方法
連休のあいだもCatyの手直しをしている。Caty devのissueにも書いたのだが、ミッシングリングが見つかってあまりにも気分がスッキリしたのでコッチにも書いておこう。以下、割とちゃんとした説明。
RPCってのは、1980年代/90年代からあって、HPの仕事をしていたときにアポロ(って会社、HPに買われた)が作ったNCS(Network Computing System)をベースにしたRPC(DCE/RPC)を使ったことがある。時代は変わった? 進化した? いや、むしろ退化したようだ。十数年も経過して、まともにRPCできる環境がない。
今RPCやるなら、HTTP上に載せるしかない。独自プロトコルはさすがに無理だろう。RPC over HTTPというと、多くの人がSOAPを思い出して「あんなもんは…」となるわけで、RPCを貶めた点でSOAPの罪は重い。
RPCはかなりのネガティブキャンペーンにさらされた。擁護するために書いた記事のひとつは次:
CatyはRPCにも向いた作りにしようと思っていたのだが、実際にRPCっぽいことやろうとするとナーンカ使いにくい。その原因は自動変換だろう、とは思っていた。
- Catyとデータ型: だれががんばるの? (2010年10月)
最近になってやっと「自動変換をやめて、それからどうするか?」が分かった。ほとんどの問題は「基本に戻れば解決する」が、今回も伝統的・古典的な常識に基づいて考えればよかったのだ。ネットワークの教科書に必ず出てくるN層アーキテクチャ。
次の3階層を使う。
- 応用固有のデータ型と処理からなる Semantic層
- 一般的で共通性が高いフォーマットからなる Generic層
- 転送に使われるデータと転送方式からなる Raw/Transport層
各階層の間の変換処理と転送処理は次のように名付ける。
- untranslate -- 送信側の、Semantic層データ→Generic層データ という変換
- unparse -- 送信側の、Generic層データ→Raw/Transport層データ という変換
- 転送処理 -- 後で出てくる。
- parse -- 受信側の、Raw/Transport層データ→Generic層データ という変換
- translate -- 受信側の、Generic層データ→Semantic層データ という変換
通信の両端にスタックがあるので、お馴染みの絵が描ける。ただし、boxes-and-wires記法を使う。箱が処理で、ワイヤーがデータ型とデータの流れを表す。
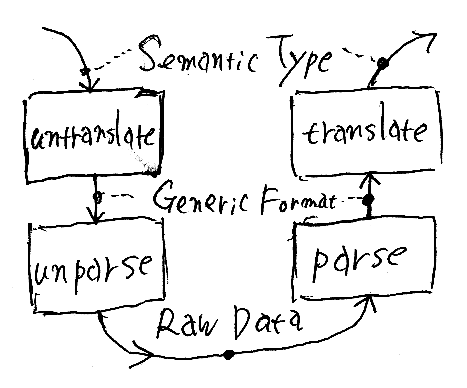
Raw DataがHTTPトランスポート上を流れる、と考えればいい。この絵は、左上から下に降りて(downward)、右に写ってから上に登る(upward)。時間の順に直列に並べると、次の絵。時間は上から下に流れる。
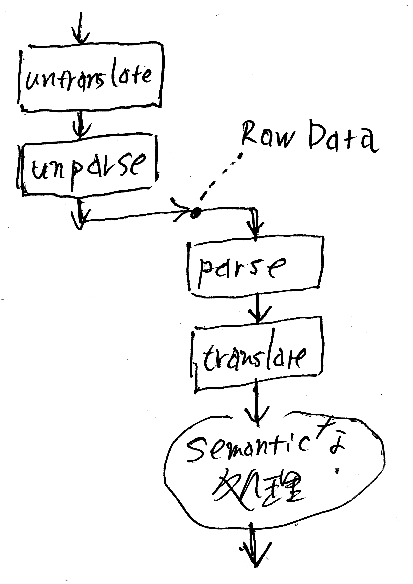
「semanticな処理」と書いてある部分が実際には重要な処理で、その他の部分はデータ変換と転送である。one-way通信の場合はこの絵でよいが、同期呼び出しのように処理結果を戻す場合はさらに「戻し」の処理が入る。HTTP上での「戻し」を含めた全体は次の絵になる。使うHTTPメソッドはpostだとしている。
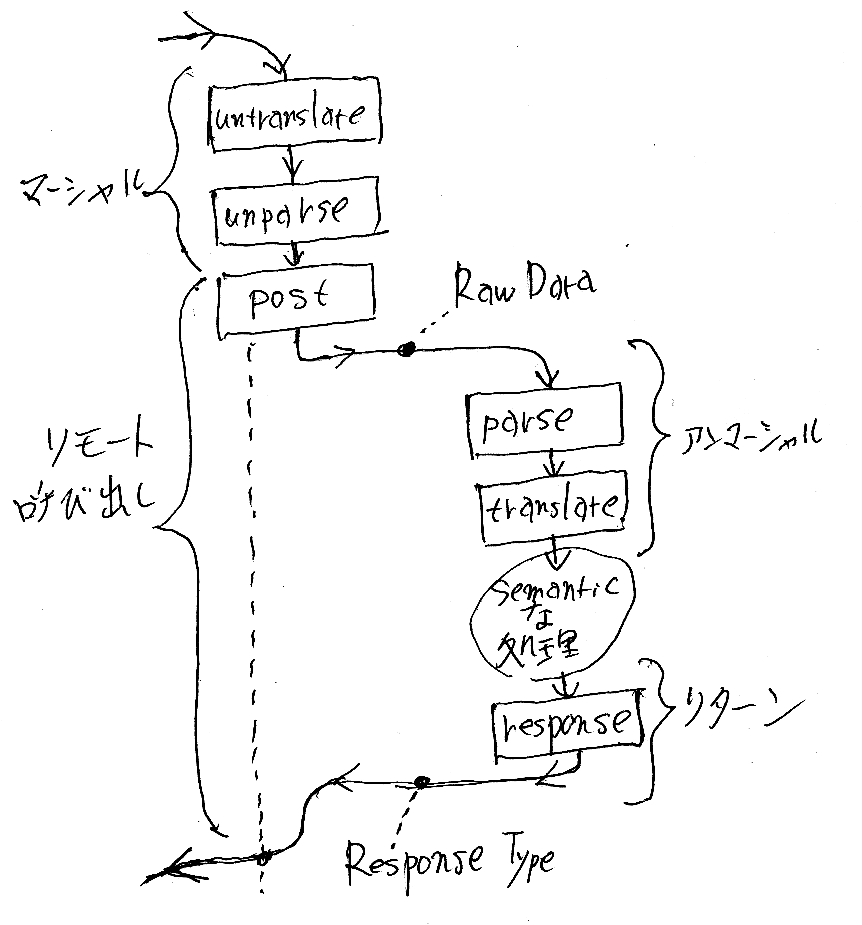
同期呼び出しなので、呼び側は戻るまでのあいだ「待ち」に入る。それが左の点線。呼ばれたサーバーは「semanticな処理」を済ませてからreturnするが、HTTPではreturnにresponseを使う。
一連の処理は、「マーシャリング、送信、アンマーシャリング、処理、リターン」となり、まさにRPC。HTTPは、リターン時のマーシャリング/アンマーシャリングをあまり意識しないで済む。しかし、レスポンスデータから「semanticな戻り値」を取り出す操作もあるから、これも絵に描くべきだったかもしれない。絵にはないが、戻り値を取り出す操作をextractとしよう。
すると、RPC over HTTPに必要な操作は、(時間順に)次のようになる。
- untranslate
- unparse
- get, put, post, head, delete (HTTPメソッド)
- parse
- translate
- process (実際の処理)
- response
- extract
いつもすべてが必要なわけではない。例えば、putでファイルを書く場合は:
- put
- process(ファイルを書く)
- response
これでOK。ローレベルで完結することは、変換なしで簡潔に出来なくてはならない。余計な変換が入ると階層が歪んで変なことになる。
processは、それぞれの応用固有の処理だから個別に書くことになるが、あとはだいたい汎用コマンドでまかなえると思っている。特に、get/put/postなどのHTTPメソッドによるリクエストとレスポンスの戻しは決まり切った処理だ。階層間でのデータ変換を行う untranslate/unparse/parse/translateもだいたいは決まりものだろう -- 変換のカスタマイズのためにプラグイン方式にしたほうがいいけど。extractは個別に書くこともあるかもしれない。
以上の手順を、ものすごくおおざっぱにCatyScriptで書くと:
/** RPCを呼ぶ側 */
command call-web [uri target] :: A -> B
{
%1 > target;untranslate |
unparse |
post %target | // ここで行って戻ってくる。
extract
};/** 呼ばれる側 */
command callee :: Raw -> Response
{
parse |
translate |
process |
response
};
call-webは、ほんとにHTTP POSTリクエストを実行するのだが、ローカルでエミュレーションするなら、call-webを次のように書き換えればいい。
/** RPCを呼ぶ側 エミュレーション */
command call-web [uri target] :: A -> B
{
%1 | to-local-target > target;untranslate |
unparse |
emu:post %target | // ローカルでエミュレーション
extract
};
calleeは、Raw -> Response というプロファイルなので、post %target をcalleeで置き換えてもいい。
/** RPCを呼ぶ側 caleeを呼んでしまう */
command call-web [uri target] :: A -> B
{
// %1 は使わないuntranslate |
unparse |
callee | // callee呼び出し
extract
};
processは A->B というプロファイルだから、すべてをすっ飛ばしてprocessを呼んでも同じ事だ。
/** RPCを呼ぶ側 processを呼んでしまう */
command call-web [uri target] :: A -> B
{
// %1 は使わない
process
};
これら、色々な呼び出し方を、いちいち手で修正せずに、設定とか環境変数で入れ替えることも出来る。アプリケーションコードでは、call-webのようなラッパーを経由して処理本体(process)を呼び出しているなら、本物のネットワークから直接コールまで、どんな形態でも実験/テスト/本番運用ができる。
こんな自由さが欲しくてパイプライン方式を採用しているのに、ちょっとした歪み(不健全な階層化)がパイプを詰まらせてしまっていた。古典と基本に戻るのが遅きに失した感もあるが、ともかくもパイプは繋がった。